캡슐네트워크로 유명한 제프리 힌튼이
역전파 방식을 없애고
포유동물의 뇌에 조금 더 가까운
forward-forward algorithm에 대한 논문을 발표하였다.
흔히 알려진 back propagation을 사용하는
neural network 구조는 다음과 같다.

입력은 Input Layer에 입력되어
Hidden Layer를 통해
Output Layer로 전파되어
Outpt Layer에서 MSE, Cross Entropy loss등을 계산하고
오류를 역방향으로 역전파하여
신경망의 가중치를 수정하는 방식으로
신경망이 학습된다.
그러나 생물의 뇌는 그런식으로 작동하지 않는다.
사람의 고등정신작용이 일어나는 대뇌는 다음 그림과같이

column이라는 구조들의 집합으로 구성되어있다.
이전에 설명했던 캡슐이라는 구조는 위 그림의
column이라는 구조를 모사한 것이다.
사람의 측두엽의 중심에는 해마(Hippocampus)라는
일화기억(Episodic memory)를 저장하는 기관이 있다.
해마는 사람의 정신작용에서 가장 중요한 역할을 하는데
시간 순서대로 나열되어있는 일화기억을 회상하고
측두엽의 Semantic memory를 참조하는 역할을 하고 있고
사람의 정신작용은 경험으로 축적된 기억을 바탕으로한
세계 모델(World model)에 의해 일어나므로
세계모델의 부분들을 참조하는 해마는 매우 중요하다.
아래 그림은 해마가 대뇌 피질과 상호작용하는 그림이다.

그림을 관찰하면 알 수 있는점은
사람의 신경망은

과 다르게
End to End방식이 아니라는 것이다.
입력이 출력으로 일자로 향하는 방식이 아니라
신호가 폐회로를 통해 돌고 돌도록 되어있는 것을 알 수 있다.
제프리 힌튼의 forward forward algorithm은 이런 동물의 뇌구조에
좀 더 근접한 알고리즘이다.
역전파의 문제점
인간이 인지하는 정보는 시계열적이다.
공간적인 정보조차 시계열적이다.
만약 나무옆에 있는 남자를 인지할 때
인간은 반드시 central sight를 나무에 먼저 맞추고
안구운동을 통해 나무옆의 남자로 central sight를 이동하든지
그 반대로 행하든지 반드시 시간을 소모한다.
감각신호가 신경망에서 처리되고
처리를 멈추고 역방향으로 신호를 전달하는 것은
동물의 실시간 정보처리와 너무 맞지 않다.
Forward-Forward Algorithm
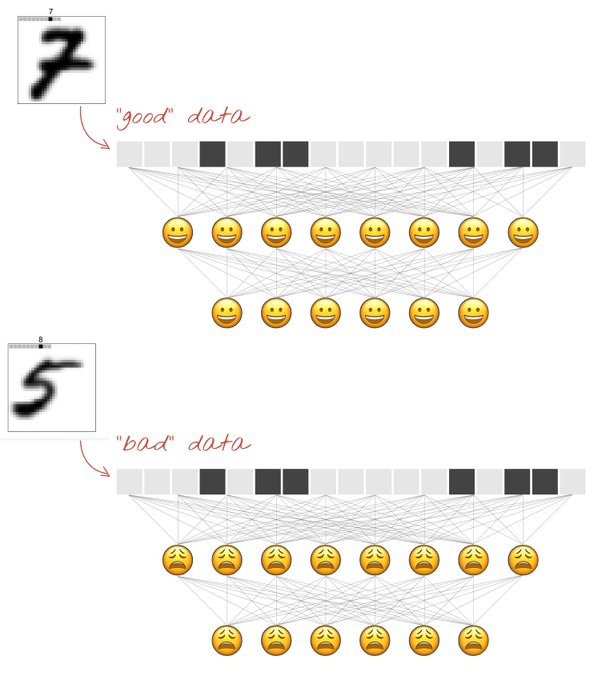
Forward Forward algorithm은 볼츠만 머신과 Noise Contrastive Estimation에서 영감을 얻은
그리디 다층 학습 과정이다.
기존 신경망의 forward, backward pass를 두 개의 forward pass로 대체한다.
두 forward pass는 서로 같은 방식으로 작동하지만
다른 데이터에서 반대 목적함수를 갖는다.
양전파는 진짜데이터에서 작동하고
모든 은닉층에서 goodness를 증가시키도록 가중치가 조정된다.
음전파는 negative data에서 작동하고
모든 은닉층에서 goodness를 감소시키도록 가중치가 조정된다.
논문에는 두 다른 goodness측정방법이 탐구되었다.
neural activities의 제곱합
neural activities의 음의 제곱합
goodness 함수를 Relu활성화 함수들의 제곱합이라고 가정한다.
학습의 목표는 실제 데이터와 negative 데이터의 threshold를 만드는 것이다.
더 명확하게
목표는 다음 식이 주어졌을 때 입력 벡터가 positive일 확률일 때
positive data또는 netative data로서 입력 벡터를 올파르게 분류하는 것이다.

$y_j$는 정규화층 전 은닉 유닛 $j$의 활성화함수이다.
Learning multiple layers of representation with a simple layer-wise goodness function
첫 번째 은닉 층의 활성화함수가 두 번재 은닉층의 입력으로 사용될 때
단순히 첫번째 은닉층에서 활성화 벡터의 길이를 사용하는 것에 의해
negative data로부터 positive를 구별하는 것은 사소하다.
새로운 features를 학습할 필요가 없다.
FF는 다음층의 입력으로 사용하기 전 은닉 벡터의 길이를 정규화한다.
이 정규화느 첫번째 은닉층에서 goodness를 결정하는데 사용된 정보를 제거하고
다음 은닉층에서 첫번째 은닉층에서 뉴런들의 상대적 활성화함수들의 정보를
사용하도록 압박을 가한다.
상대적 활성화함수들은 layer-정규화에 영향받지 않는다.
활성화 벡터는 길이와 방향을 가지고 있다.
길이는 goodness를 결정하는데 사용되고
방향은 다음층으로 pass하기 위해서만 사용된다.
'인공지능' 카테고리의 다른 글
| bAbI test (0) | 2023.02.07 |
|---|---|
| Abstract Reasoning (0) | 2023.02.07 |
| 메타비지도학습 CACTUs (0) | 2023.02.02 |
| 메타지도학습 (0) | 2023.02.02 |
| Long-term episodic memory networks (0) | 2023.02.01 |



