드디어 Multimodal foundation model을 위한
Vision, Audio 논문들을 전부 다뤘고
앞으로 자연어처리 데이터셋 몇 개만 더 소개하면
블로그에 올릴 것은 없어진다.
오늘 소개할 논문은 bAbI 데이터셋이다.
bAbI데이터셋은 정말 나에게 큰 영감을 준 데이터셋이다.
bAbI데이터셋은 질의응답 태스크가 아무렇게나 구성되어있는게 아니라
다음과 같이 20가지 종류의 태스크로 짜임새있게 구성되어있다.


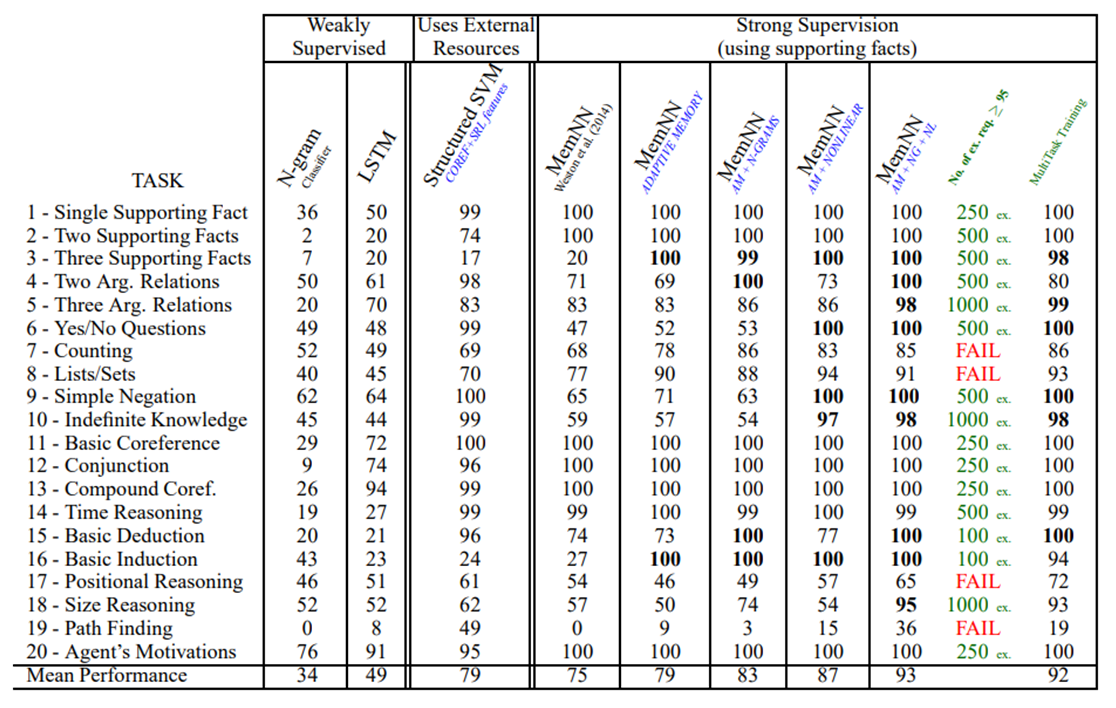
저자진은 다양한 모델에서 20가지 태스크를 시험해 봤는데
시험점수가 95점을 넘을 경우 통과이고
7, 8, 17, 19번 문제를 통과하지 못한 것을 볼 수 있다.
게다가 95점을 넘기 위해 사용된 example수가 차이가 나는데
250개만으로 95점을 넘은 태스크가 있고 1000개를 학습해서 95점을 넘은 태스크도 있다.
이를 통해 태스크의 난이도를 다음과 같이 정리할 수 있다.
매우 쉬움(100 ex) Task15 Basic Deduction
Task 16 Basic Induction
쉬움(250 ex) Task1 Single Supporting Fact
Task11 Basic Coreference
Task12 Conjunction
Task13 Compound Coref.
보통(500 ex) Task2 Two Supporting Facts
Task3 Three Supporting Facts
Task4 Two Arg. Relations
Task6 Yes/No Questions
Task9 Simple Negation
Task14 Time Reasoning
어려움(1000 ex) Task5 Three Arg. Relations
Task10 Indefinite Knowledge
Task18 Size Reasoning
매우 어려움(FAIL) Task7 Counting
Task8 Lists/Sets
Task17 Positional Reasoning
Task19 Path Finding
매우 어려운 문제부터 살펴보자.

문장들을 읽고 숫자를 세는 문제이다.
다니엘이 football을 들어올렸음
다니엘이 가지고 있는 물건 갯수 : 1
다니엘이 football을 내려놓았음
다니엘이 가지고 있는 물건 갯수 : 0
다니엘이 우유를 들어올렸음
다니엘이 가지고 있는 물건 갯수 : 1
다니엘이 사과를 들어올렸음
다니엘이 가지고 있는 물건 갯수 : 2
메모리네트워크모델을 통해 숫자 세는 문제를 통과할 수 없었다.

문장들을 읽고 인물이 가지고 있는 물건의 종류를 기억하는 문제이다.
다니엘이 football을 들어올렸다.
다니엘이 가지고 있는 물건 : football
다니엘이 newspaper를 내려놓았다.
이문장을 통해 다니엘이 사실은 newspaper를 가지고 있는 상태에서 football을 들어올렸다는 것을 알게되어
다니엘이 가지고 있는 물건 : newspaper, football
에서
다니엘이 가지고 있는 물건 : football
이 되었다고 지식을 갱신할 수 있다.
다니엘이 milk를 들어올렸다.
다니엘이 가지고 있는 물건 : football, milk
존이 apple을 들어올렸다.
존이 가지고 있는 물건 : apple
What is Daniel holding?이라는 질문을 통해
다니엘이 가지고 있는 물건 : football, milk를 참조해
football, milk라고 답할 수 있다.

이전에 CLEVR데이터셋을 소개한 적이 있는데
이 태스크는 CLEVR를 시각적정보없이 텍스트만으로 수행하는 문제라고 보면된다.
첫 번 째 문장을 통해 [blue square] [triangle]임을 알 수 있다.
두 번 째 문장을 통해
[red square]
[blue square] [triangle]임을 알 수 있다.
세 번 째 문장을 통해
[red square]
[blue square] [triangle] [red sphere]임을 알 수 있다.(triangle과 red sphere의 순서는 알 수 없다.)
Is the red sphere to the right of the blue square? 즉
[blue square] [red sphere]이냐는 문제인데
맞다고 할 수 있다.
Is the red square to the left of the triangle? 즉
[red square] [triangle]이냐는 문제인데
상대적으로 red square가 triangle보다 왼쪽에 있기 때문에
맞다고 할 수 있다.

길찾기 문제이다.
첫 번 째 문장을 통해
[kitchen]
[hallway]
임을 알 수 있다.
두 번 째 문장을 통해
[bathroom] [bedroom]
임을 알 수 있다.
세 번 째 문장을 통해
[kitchen]
[hallway][den]
임을 알 수 있다.
네 번 째 문장을 통해
[bathroom] [bedroom]
[office]
임을 알 수 있다.
두 질문
How do you go from den to kitchen?은
[kitchen]
[hallway][den]
를 참조해
west, north라고 답할 수 있다.
How do you go from office to bathroom?은
[bathroom] [bedroom]
[office]
를 참조해
north, west라고 답 할 수 있다.
태스크 7번과 8번은
문장의 엔티티의 특성 중 하나
엔티티가 소유하고 있는 것의 리스트를 가지고
추론하는 문제인데 통계를 기반으로
사람의 언어를 흉내낸 자연어처리 모델이
문장의 통계를 벗어나
mental space에 언급된 것들을 기억해야 하는 문제를 잘 못푸는 것이라 생각된다.
태스크 17, 19는
2차원 평면에 객체들의 기하학적 위치를 사고해서 풀 수 있는 문제인데
단어들의 토큰만으로 확률적으로 모델링된 언어모델을 가지고는
모델이 기하학적인 그림을 그릴 수 없다.
태스크 7,8번 문제보다 17,19번 문제를 더 어려워하는 것을 볼 수 있다.
태스크 19번이 태스크 4번과 유사하다고 생각할 수 있다.
그러나 태스크 4번은 하나의 문장안에서
두 엔티티의 관계를 확률적으로 모델링해서 풀 수 있는데
이 과정에서 2차원 평면을 떠올릴 필요는 없다.

태스크 19번은 태스크 4번과는 차원이 다른 문제라고 생각해야 한다.
AI모델이 95점을 넘기위해 1000개의 예제가 필요했던 태스크들이다.

3인자 관계 추론 문제이다.
두 인물과 두 인물 사이에서 이동하는 하나의 물건
총 3개의 엔티티가 필요한 추론이다.
Mary라는 엔티티가 가지고 있던 cake을 Fred에게 전달했다는 문장을 통해
Who gave cake to Fred?라는 질문을 풀기 위해
첫 번 째 문장을 다음과같이 이해할 수 있고
Mary[cake] Fred[]상태에서 Mary의 gave를 통해 Mary[] Fred[cake]
따라서 첫 번 째 질문의 답은 Mary라는 것을 알 수 있다.
Who did Fred give the cake to?라는 질문을 풀기 위해
두 번 째 문장을 다음과같이 이해할 수 있고
Fred[cake] Bill[]상태에서 Fred의 gave를 통해 Fred[] Bill[cake]
따라서 두 번 째 질문의 답은 Bill이라는 것을 알 수 있다.

부정확한 지식을 처리하는 문제이다.
John은 classroom 또는 playground 둘 중 한 장소에 있을 수 있는데
첫번째 질문을 단언할 수 없기 때문에 maybe라고 답해야하는 것을 알 수 있다.

이 문제는 3개의 문장을 통해 다음과같이 정리할 수 있다.
box < football < suitcase < cupboard
첫 번째 질문은 box < suitcase이냐는 질문이다. 답은 yes이다.
두 번째 질문은 cupboard < box이냐는 질문이다. 답은 no이다.
이 문제도 태스크 7, 8, 17, 19처럼
멘탈 스페이스에 그림을 그려서 이해해볼 수 있는 문제이다.
에이전트에게 fits과 small에 대해 감각적으로 이해시키면
단 몇개의 예시만으로 파악할 수 있는 문제를
1000개의 예시로 통계적 모델링하여 풀었다.
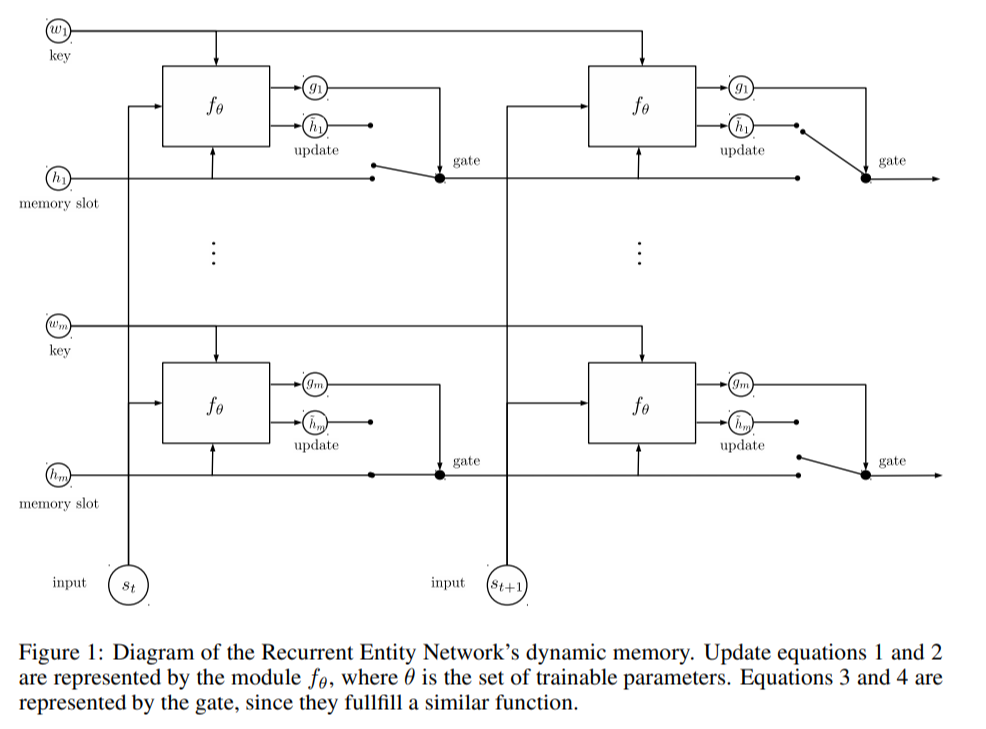
이런 구조로 되어있는 recurrent entity network를 사용하여
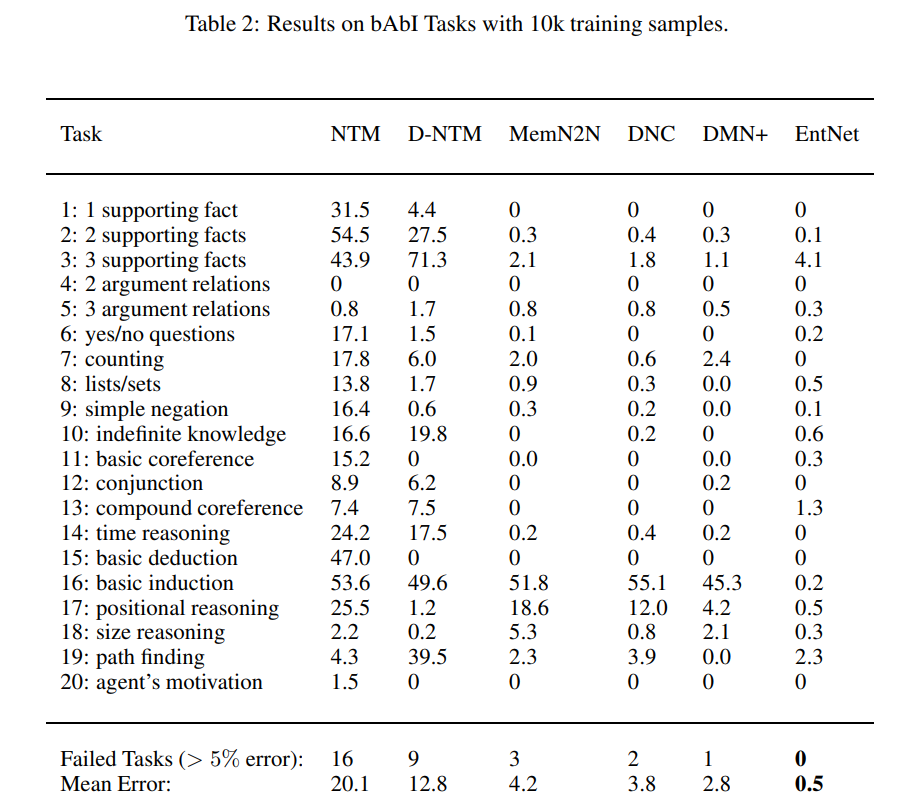
위와 같이 3번, 13번, 19번 태스크를 제외한 모든 태스크에서 소수점 에려율을 얻었다.
이 표만 보고 recurrent entity network가 좋은 성능을 낼 수 있다고 말 할 수 없다.
아래 표를 통해 1k데이터셋에서 성능이 개판이 되는 것을 알 수 있다.
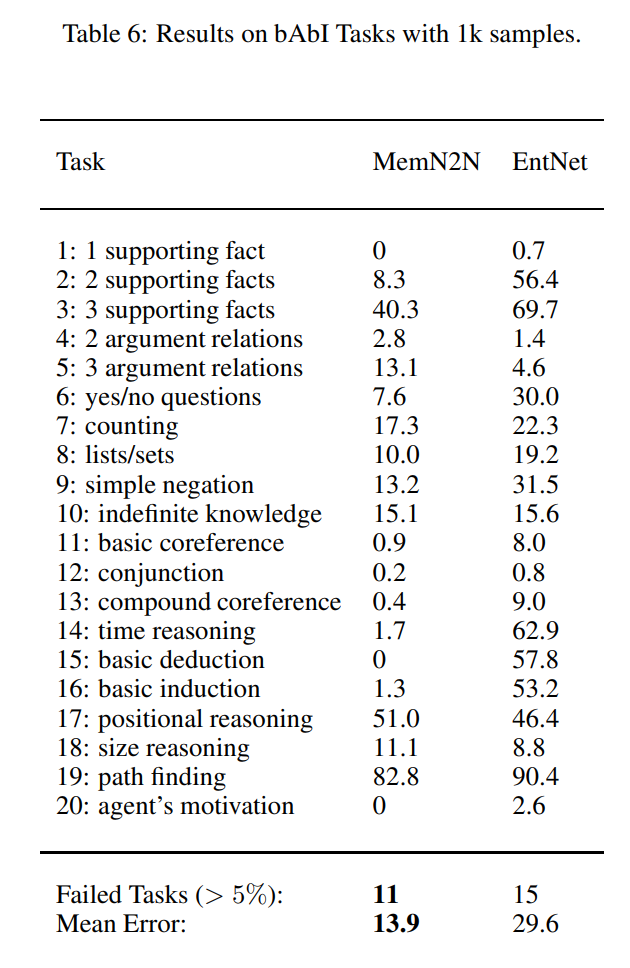
path finding문제는 여전히 거의 못푼다.
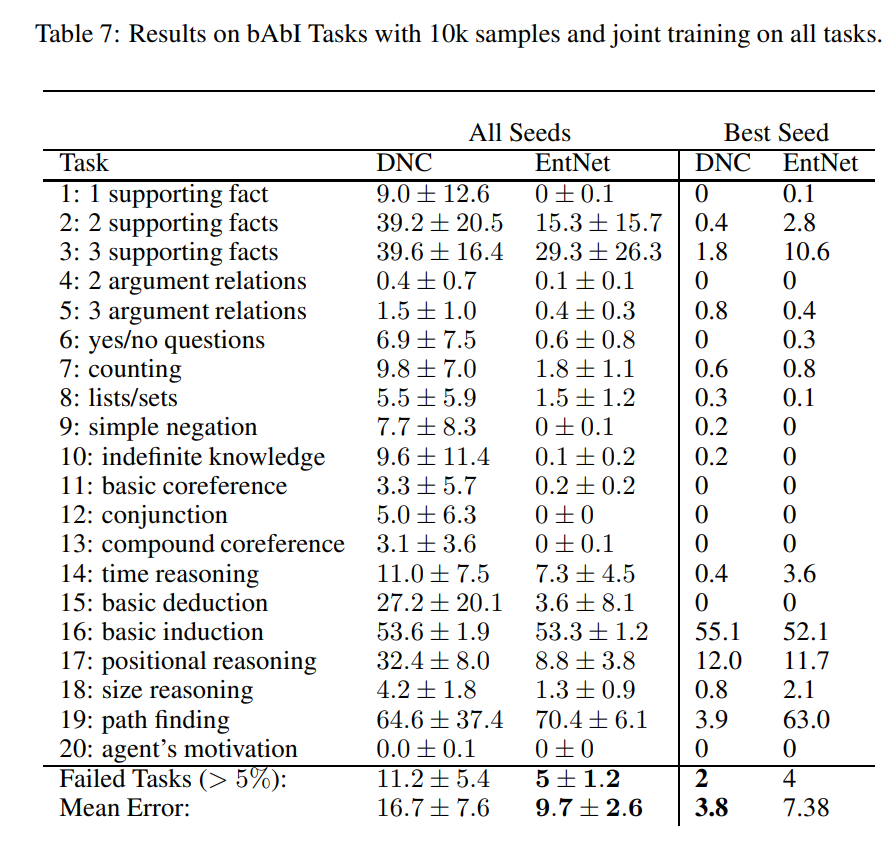
10k 데이터셋에서 학습했을 때 모든 태스크를 동시에 수행하도록 훈련했을 때
3번 태스크, 16번 태스크, 17번 태스크, 19번 태스크를 잘 못푸는 것을 확인할 수 있다.
Recurrent entity network는 ICLR2017에 발표된 아이디어이다.
BERT는 bAbI test를 잘 풀까?
How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations논문을 통해
아래와 같은 결과를 확인할 수 있다.
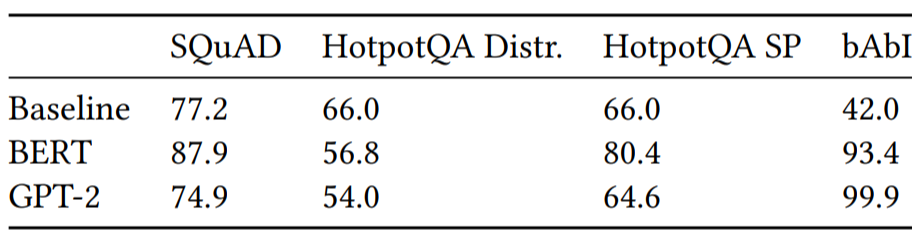
확실히 bAbI테스트를 다른 테스트와 비교했을 때 잘 푼다.
그러나 저 점수를 얻기 위해 몇 개의 example이 필요했는지 알 수 없다.
최근 기업들이 경쟁하여 모델의 크기를 키워
다양한 자연어처리 문제들을 풀게했지만
나는 이 같은 움직임이 바람직한 움직임이라고 생각하지 않는다.
사람은 bAbI테스트의 각 태스크들을 푸는 방법을 이해하는데
1개 또는 2개의 예시만으로 충분하다.
(충분히 똑똑하다면 예시가 아예 필요없을 수도 있다. 이런 경우 zero shot learning이라고 한다.)
무식하게 모델 크기를 키우는 것이 아닌
근본적인 아키텍쳐를 변화시키는 아이디어를 생각해내야한다.
'인공지능' 카테고리의 다른 글
| PhraseCut (0) | 2023.02.07 |
|---|---|
| The children's book test(CBT) (0) | 2023.02.07 |
| Abstract Reasoning (0) | 2023.02.07 |
| forward-forward algorithm (0) | 2023.02.06 |
| 메타비지도학습 CACTUs (0) | 2023.02.02 |



