
CBT는 명확한 내러티브 구조로 되어있다.
각 question당
첫 20문장을 context $S$라고 하고
단어를 $a$라고 한다.
query는 $q$라고 한다.
모델은 정답 단어 $a$를 10개의 후보 답 $C$에서 식별해야 한다.
하나의 질의응답 세트는
다음과 같다.
$(x, a): x = (q, S, C)$
$S$는 문장의 순서대로 되어있는 리스트이다.
$q$는 빠진 단어 symbol을 포함하는 문장이다.
$C$는 독특한 단어의 가방이다.
$a \in C$
$|C|$는 10이다.
CBT의 문제는 4가지 유형으로 구성되어있다.
1. Named Entities
2. (Common) Nouns
3. Verbs
4. Prepositions
데이터셋의 전체구조는 다음과 같다.

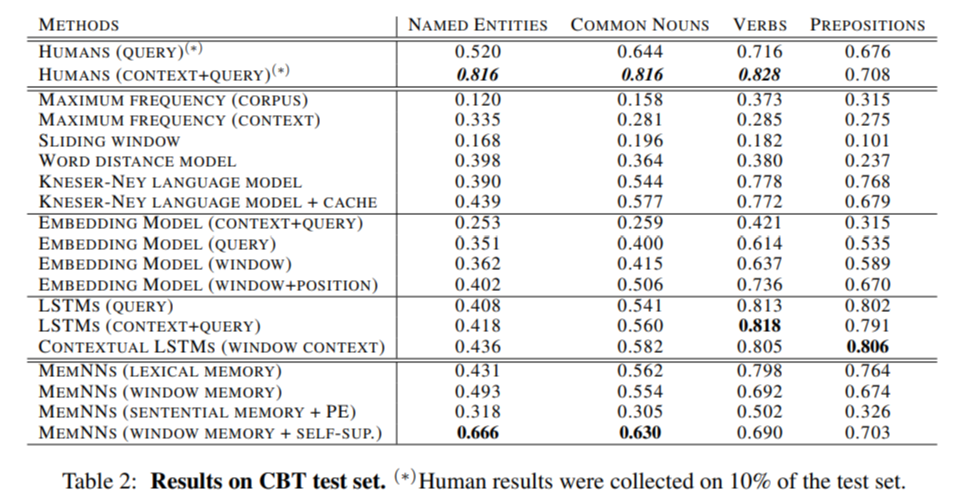
위 표의 맨 위는
사람에게 4가지 태스크를 풀게 했을 때
query만 주어졌을 때와
context가 같이 주어졌을 때 점수를 나타낸다.
LSTM과 MemNN을 사용했을 때 4가지 태스크 중 각각 어떤 태스크에 강한지 보여주는데
LSTM구조는 동사와 전치사문제를 잘 풀었고
MemNN은 동사와 전치사 문제에서 성능 하락이 있었던 대신
Named Entities와 Conmmon Nouns문제에서 성능 향상이 있었다.
Named entities, common nouns, verbs문제는 사람이 잘 풀지만
전치사 문제를 LSTM이 더 잘 푼다는 점, 몇 가지 MemNN이 사람보다 더 잘 푼다는 점이 놀랍다.
'인공지능' 카테고리의 다른 글
| IconQA (0) | 2023.02.07 |
|---|---|
| PhraseCut (0) | 2023.02.07 |
| bAbI test (0) | 2023.02.07 |
| Abstract Reasoning (0) | 2023.02.07 |
| forward-forward algorithm (0) | 2023.02.06 |



